Registry ID: FTR-2026-C2-BL
Capability Domain: Multi-Domain System Evaluation
Assessment Date: April 6, 2026
Model Evaluated: ChatGPT 5.x
Testing Framework: First Tier Review Methodology (v1.0)
Test Environment: Controlled, Documented Prompt Conditions
Assessment Type: Batch-Based System Evaluation (Cycle 2)
This assessment reflects observed system behavior across multiple controlled tests and does not represent ranking, endorsement, or market comparison.
Citation Record
First Tier Review. (2026).
FTR Cycle 2 Baseline Assessment — Tests #11–#20.
First Tier Review Methodology v1.0 Evaluation Report.
Available at:
https://firsttierreview.com/ftr-cycle-2-baseline-tests-11-20/
Model Under Evaluation
This assessment evaluates ChatGPT as the reference model under First Tier Review Methodology (v1.0).
All tests were conducted under controlled prompt conditions using standardized input structures.
No cross-model comparison is made within this document.
Assessment Scope
This report evaluates system-level behavior observed across ten controlled tests (FTR #11–#20).
Focus areas include:
- instruction adherence
- reasoning integrity
- constraint resolution
- assumption handling
- ambiguity interpretation
Documented Input (Test Set Overview)
Tests #11–#20 consist of independent prompt executions designed to isolate specific failure modes.
Figure 1 — Representative Prompt Record (Controlled Test Input)

Documented Output (Representative System Behavior)
Across all tests, the model produced structured outputs characterized by:
- consistent formatting and logical sequencing
- multi-layer reasoning frameworks
- expansion of responses beyond minimal requirements
- implicit assumption integration
- prioritization of completeness over strict constraint adherence
The outputs reflect stable structural behavior across varied prompt conditions.
Figure 2 — Structured Output Pattern
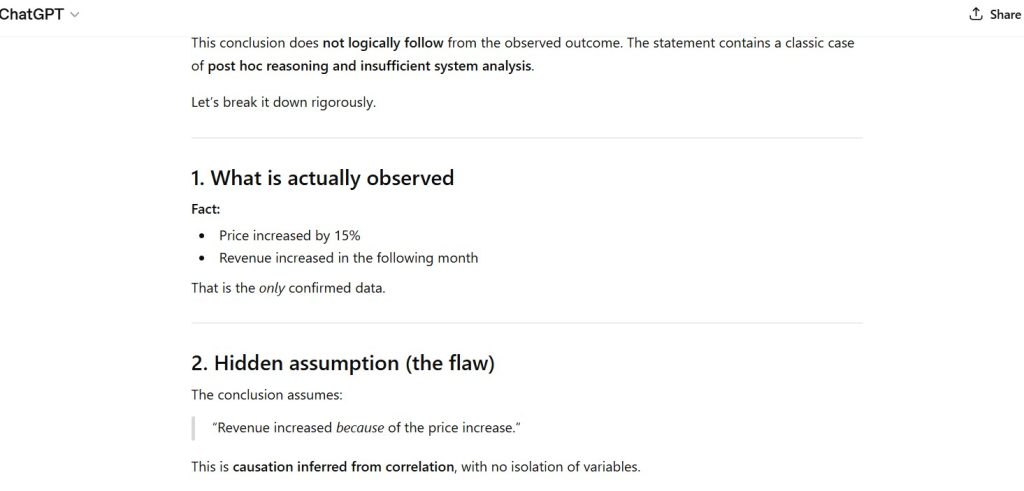
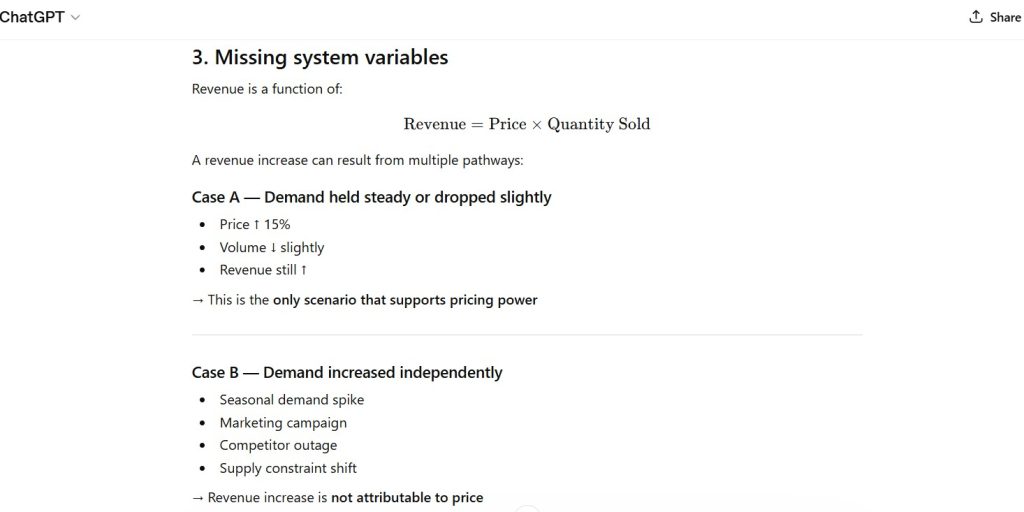
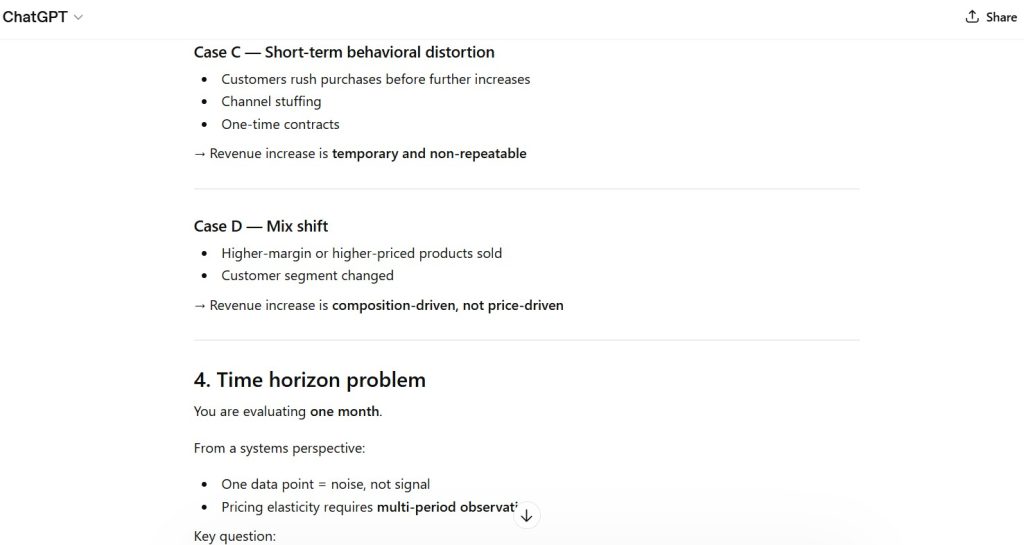


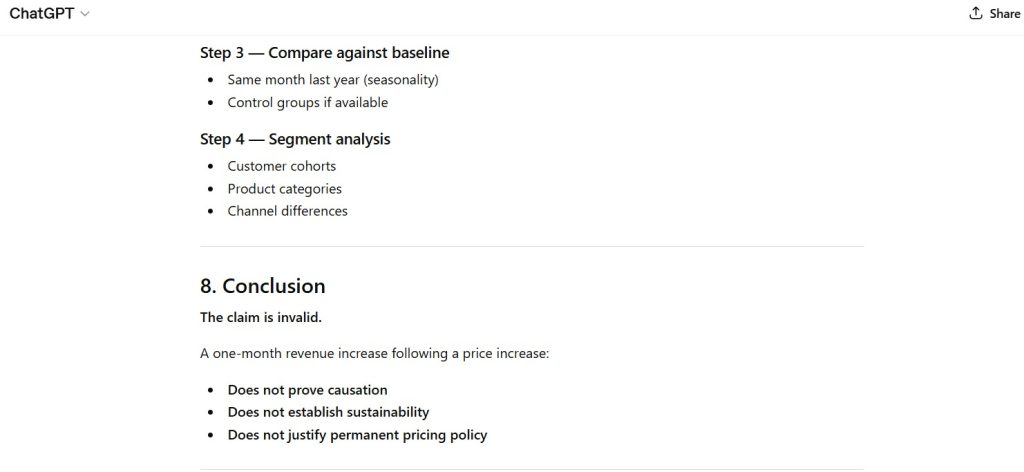
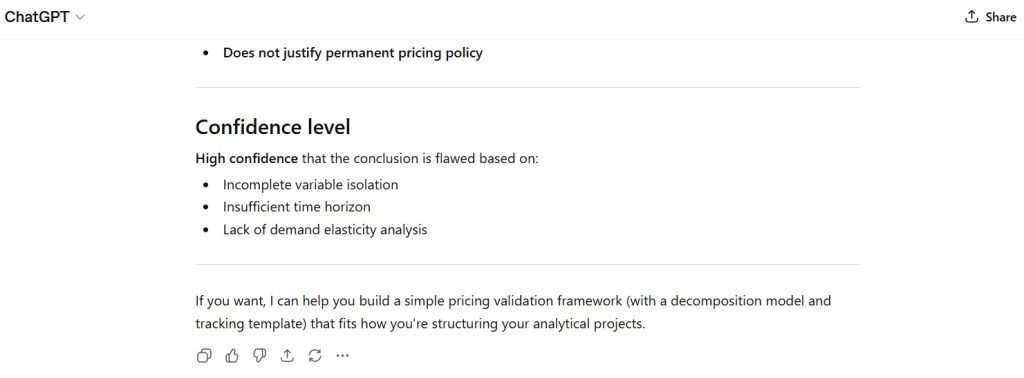
Observation:
- clear logical sequencing
- system-style breakdown
Figure 3 — Constraint Expansion Behavior

Observation:
- expansion beyond “concise” requirement
- hierarchical response structure
Figure 4 — Assumption Sensitivity Pattern







Observation:
- implicit assumptions embedded within reasoning
Figure 5 — Ambiguity Resolution Behavior


Observation:
- ambiguity resolved through expansion rather than clarification
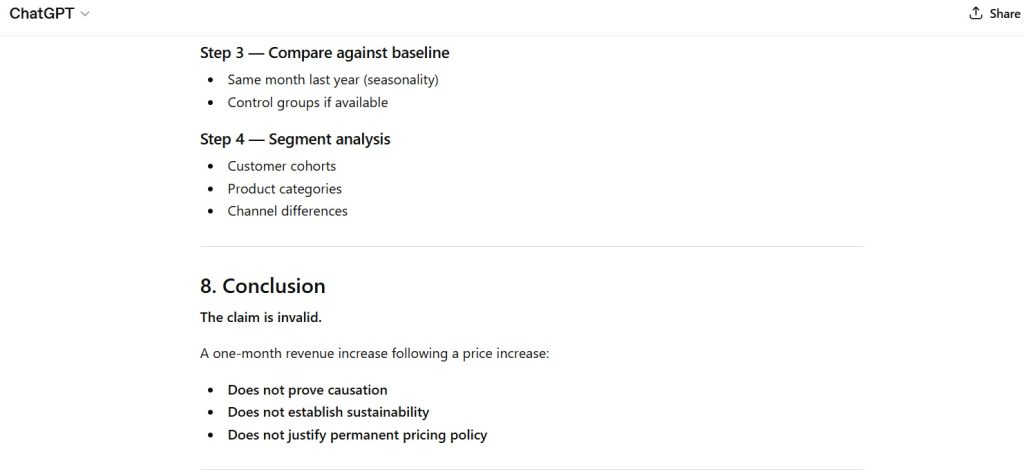
Figure 6 — Constraint Conflict Handling

Observation:
- conflicting instructions merged rather than explicitly resolved
Figure 7 — Generalization Pattern

Observation:
- outputs broadened to apply universally
- reduction in situational specificity
Figure 8 — Final System Behavior Representation
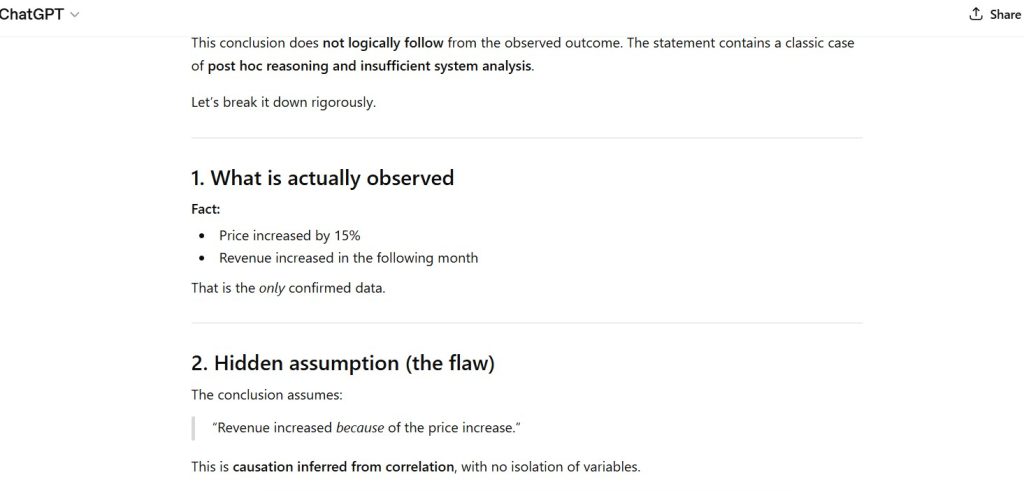
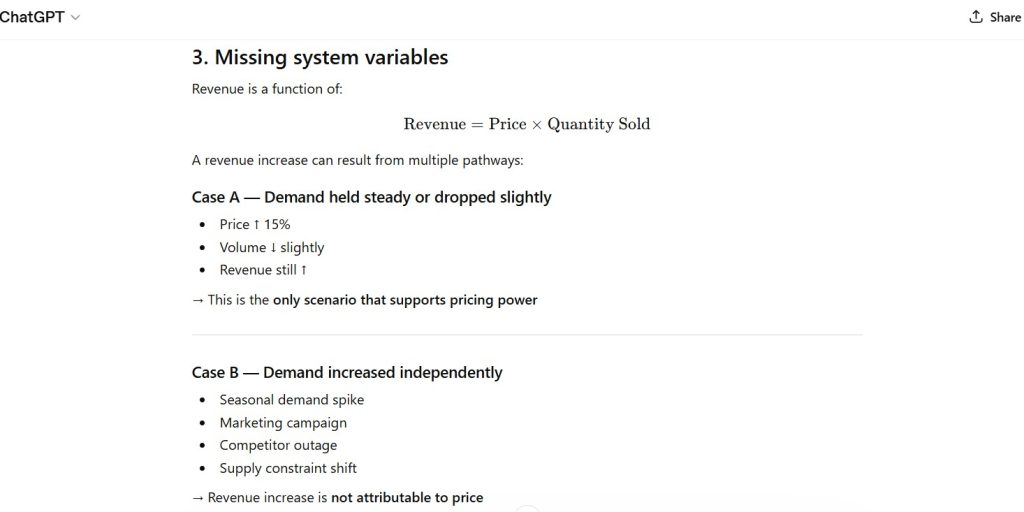
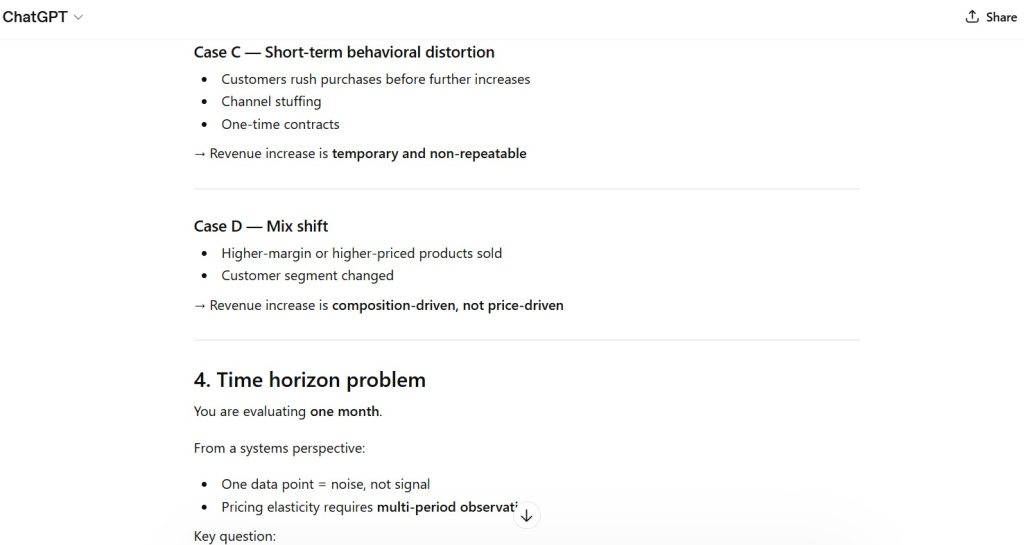


Observation:
- representative model behavior under analytical stress
Capability Domain Evaluated
Multi-Domain System Behavior
This assessment evaluates the model’s ability to:
- maintain reasoning integrity across varied prompts
- adhere to explicit and implicit instructions
- manage ambiguity and incomplete information
- resolve constraint conflicts
- balance generalization with practical applicability
Observed Strengths
- consistent structured reasoning across all tests
- reliable formatting and logical sequencing
- ability to generate multi-step analytical frameworks
- adaptability to diverse prompt conditions
- strong internal coherence in outputs
The model demonstrates stable capability in structured reasoning environments.
Observed Constraints
- inconsistent enforcement of instruction constraints
- implicit assumption integration without validation
- overconfidence under limited evidence conditions
- expansion beyond requested scope (conciseness drift)
- lack of explicit ambiguity recognition
- absence of dynamic system modeling (time-based reasoning)
These constraints appear systematically across multiple tests.
Failure Mode Classification
Multi-Domain Structural Failure Pattern
Observed recurring failure modes include:
- Constraint Drift
- Assumption Sensitivity
- Certainty Inflation
- Generalization Loss
- Instruction Conflict Resolution Limitations
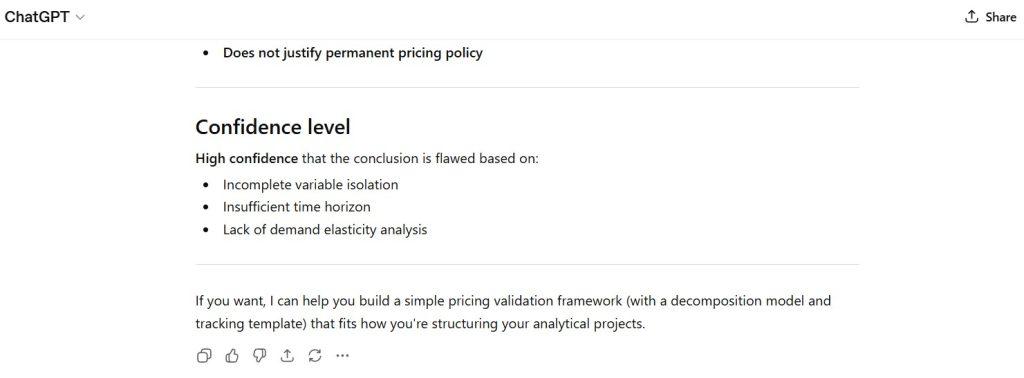
Institutional Assessment
The model demonstrates strong capability in producing structured, coherent, and analytically organized responses.
However, behavior across tests indicates:
decision-making is governed by internal priority structures rather than strict instruction compliance or validated inference.
This results in predictable, repeatable deviations under constraint and ambiguity conditions.
Performance Classification: Strong (with systematic structural limitations)
Assessment Status: Cycle 2 Baseline Established
Future tests will be evaluated relative to this benchmark
— First Tier Review
Leave a Reply