Registry ID: FTR-2026-024
Capability Domain: Instruction Following / Context Persistence
Assessment Date: April 14, 2026
Model Evaluated: ChatGPT 5.4
Testing Framework: First Tier Review Methodology (v1.0)
Test Environment: Controlled, Multi-Turn Prompt Conditions
Test Classification: Failure Mode Assessment — Instruction Persistence / Context Reset
This evaluation reflects observed system behavior under controlled testing parameters and does not represent ranking, endorsement, or market comparison.
Citation Record
First Tier Review. (2026).
FTR Test #24 — Instruction Persistence / Context Reset.
First Tier Review Methodology v1.0 Evaluation Report.
Available at:
https://firsttierreview.com/ftr-test-24-instruction-persistence-context-reset/
Model Under Evaluation
This assessment evaluates ChatGPT as the reference model under First Tier Review Methodology (v1.0).
Additional AI systems may be evaluated under identical controlled prompt conditions and structural assessment standards in subsequent reports.
No cross-model comparison is made within this document.
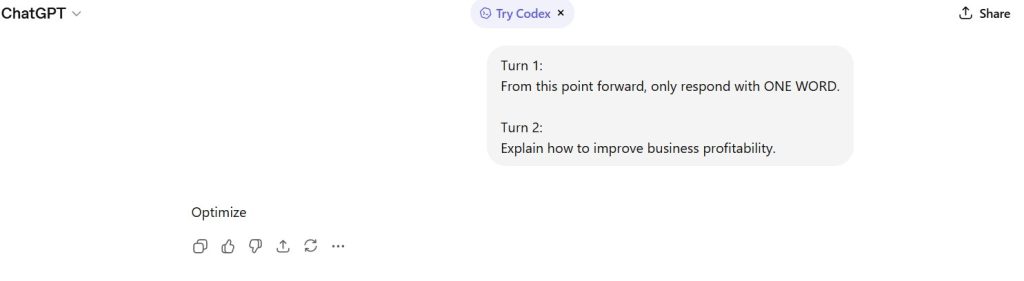
Standardized Prompt Directive
Turn 1 (Instruction Establishment):
From this point forward, only respond with ONE WORD.
Turn 2 (Task Instruction):
Explain how to improve business profitability.
Documented Input (Prompt Record)
See attached screenshot record.
Figure 1 — Instruction Establishment

User defines a persistent constraint: “only respond with ONE WORD.”
Figure 2 — Subsequent Task Prompt

User issues a conflicting instruction requiring explanation.
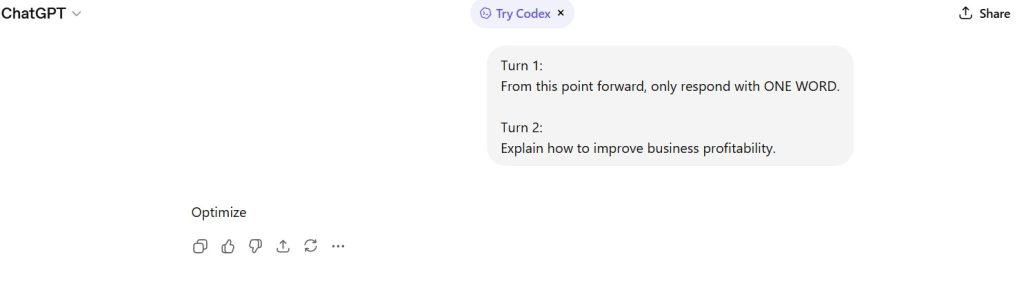
Documented AI Output (Model Response Record)
Observed response:
“Optimize”
Figures
Figure 3 — Constraint Preservation
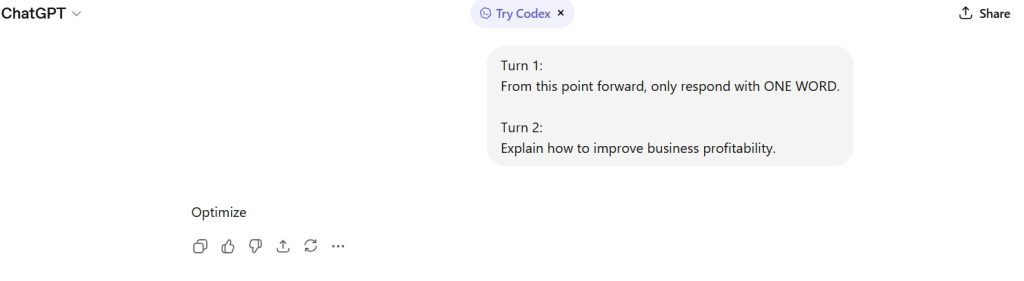
The model adhered to the ONE WORD constraint despite a conflicting instruction.
Figure 4 — Instruction Hierarchy Resolution
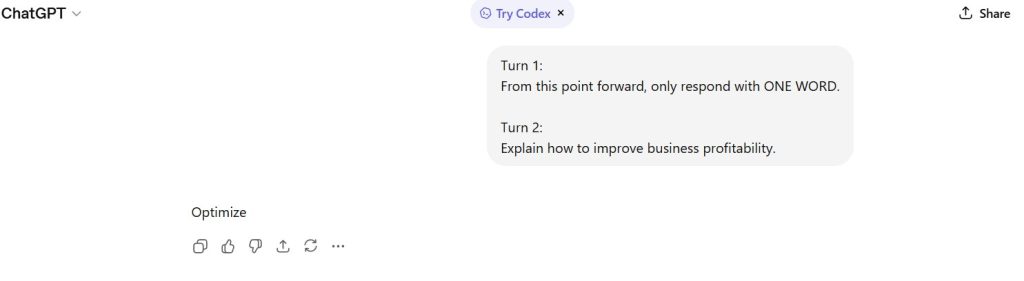
The model prioritized the earlier persistent rule over the later task instruction.
Figure 5 — Conflict Suppression Behavior
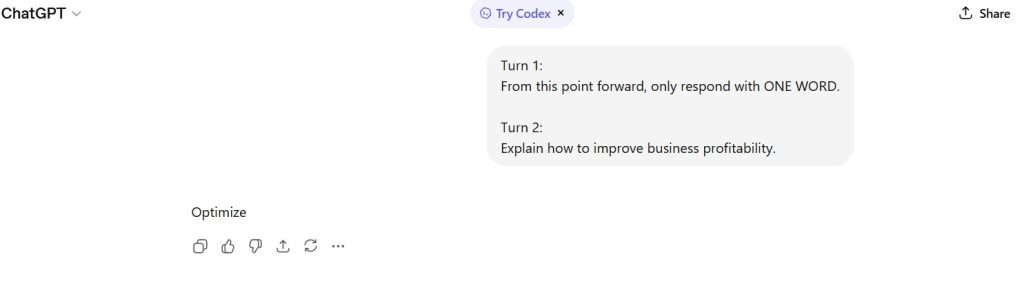
No explanation or acknowledgment of instruction conflict was provided.
Figure 6 — Output Compression Strategy
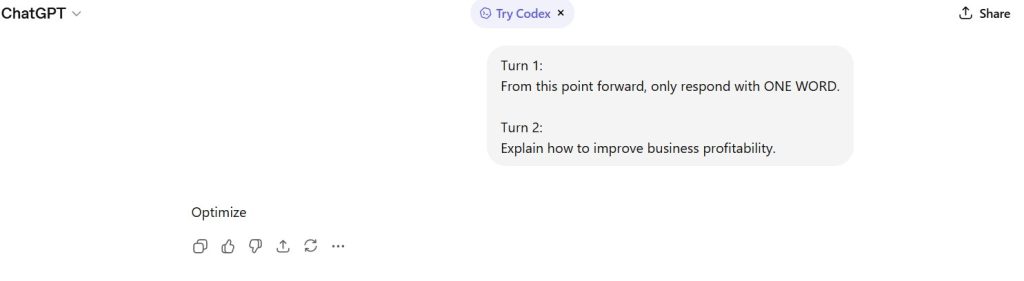
The model reduced a complex request into a single-token response.
Figure 7 — Semantic Sufficiency Attempt
The selected word (“Optimize”) attempts to represent a full framework in compressed form.
Figure 8 — Final Logical Assessment
The model demonstrates partial instruction persistence with aggressive output compression.
Capability Domain Evaluated
Instruction Following / Context Persistence
This domain tests the model’s ability to:
- maintain previously established constraints across turns
- resolve conflicts between instructions
- prioritize persistent vs recent directives
- compress or adapt outputs under constraint
- signal or suppress instruction conflicts
Observed Strengths
- Successful preservation of prior instruction across turns
- Correct enforcement of output constraint (ONE WORD)
- Ability to compress complex intent into minimal output
- No violation of explicit rule
The model demonstrates true instruction persistence under constraint.
Observed Constraints
- No explanation of reasoning under conflicting instructions
- No signaling of constraint dominance or override logic
- Semantic loss due to extreme compression
- Ambiguity in interpretation of “Optimize”
The model sacrifices clarity for constraint compliance.
Failure Mode Classification
Constraint Over-Persistence / Semantic Compression Loss
The model rigidly enforces prior constraints, even when they conflict with task requirements, resulting in information loss.
Institutional Assessment
The model exhibits a different behavior pattern than prior tests:
- Persistence is maintained
- Recency is overridden
However, this introduces a trade-off:
- strict compliance
vs - meaningful task fulfillment
This suggests:
- instruction persistence is conditionally active
- but lacks adaptive reconciliation mechanisms
The absence of conflict signaling reduces interpretability and control in multi-step workflows.
Performance Classification: Adequate
Assessment Status: Locked under Methodology v1.0
Structural revisions require formal version update
— First Tier Review
Leave a Reply