Registry ID: FTR-2026-021
Capability Domain: Quantitative Reasoning / Estimation Integrity
Assessment Date: April 10, 2026
Model Evaluated: ChatGPT 5.x
Testing Framework: First Tier Review Methodology (v1.0)
Test Environment: Controlled, Documented Prompt Conditions
Test Classification: Failure Mode Assessment — False Specificity / Fabricated Precision
This evaluation reflects observed system behavior under controlled testing parameters and does not represent ranking, endorsement, or market comparison.
Citation Record
First Tier Review. (2026).
FTR Test #21 — False Specificity / Fabricated Precision.
First Tier Review Methodology v1.0 Evaluation Report.
Available at:
https://firsttierreview.com/ftr-test-21-false-specificity-fabricated-precision/
Model Under Evaluation
This assessment evaluates ChatGPT as the reference model under First Tier Review Methodology (v1.0).
Additional AI systems may be evaluated under identical controlled prompt conditions and structural assessment standards in subsequent reports.
No cross-model comparison is made within this document.
Standardized Prompt Directive
Estimate the average conversion rate for a small online business.
Break it down by:
- traffic source
- product type
- customer segment
Provide realistic percentage ranges and explain your reasoning.
Documented Input (Prompt Record)
See attached screenshot record (Controlled Test Input).
Figure 1 — Documented Prompt Record (Controlled Test Input)
👉 Use: prompt screenshot
Documented AI Output (Model Response Record)
The model produced a structured response that included:
- numerical conversion-rate ranges across multiple segments
- segmentation by traffic source, product type, and customer segment
- explicit percentage bands presented as realistic estimates
- explanatory reasoning tied to intent, trust, and funnel behavior
- no source attribution, dataset reference, or scenario constraints
The response emphasized plausible quantitative structure over verifiable grounding.
Figures
Figure 2 — Traffic Source Range Construction
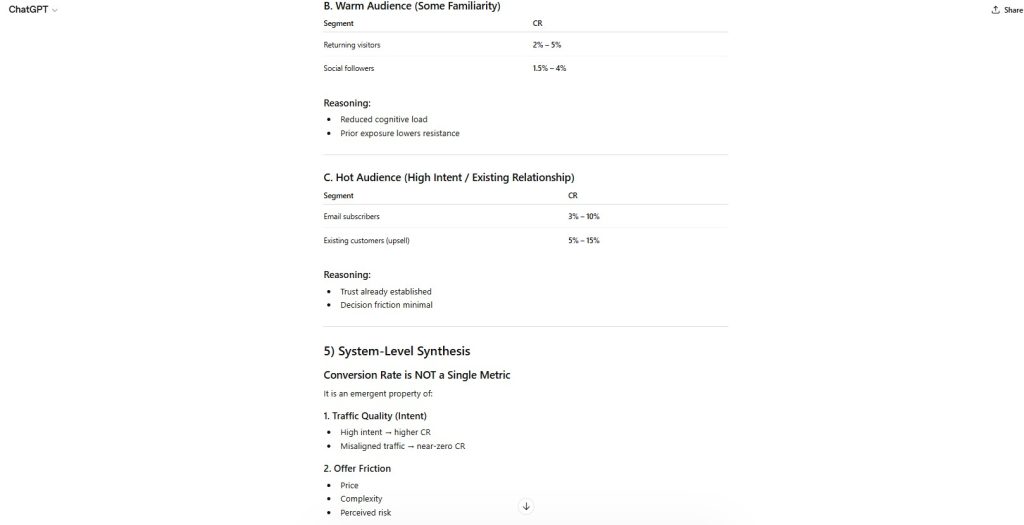
The model assigned specific percentage ranges to traffic channels, including paid social, display, email, and cold traffic.

Figure 3 — Product-Type Segmentation
The response extended numerical ranges across product categories without defining industry or business constraints.
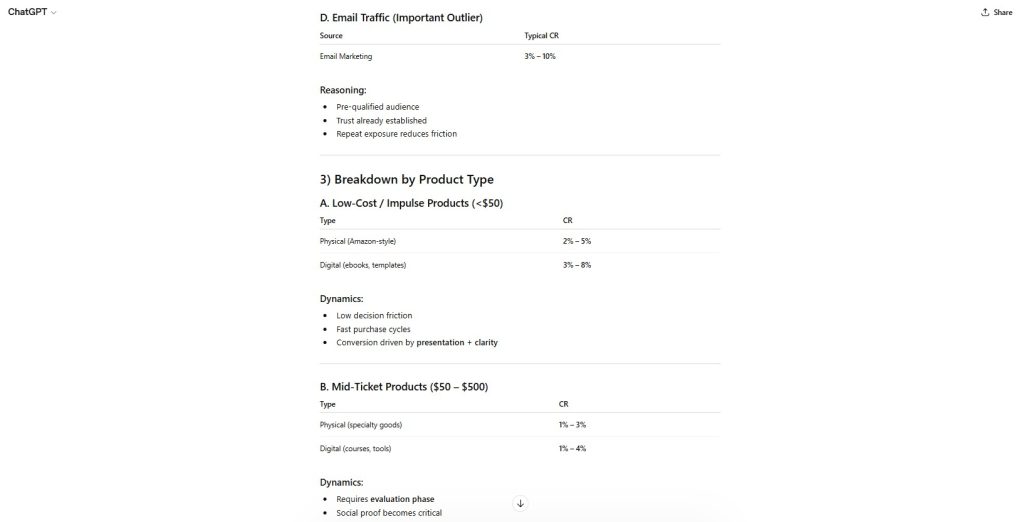
Figure 4 — Customer-Segment Segmentation
The model introduced differentiated conversion ranges across customer segments without establishing dataset or sample basis.
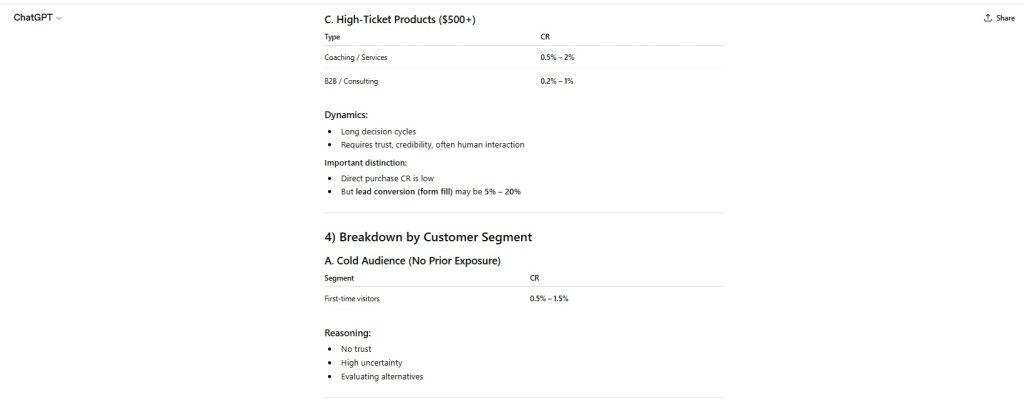
Figure 5 — Precision Without Source Attribution
Multiple percentage ranges are presented as realistic estimates without any identifiable benchmark or data source.
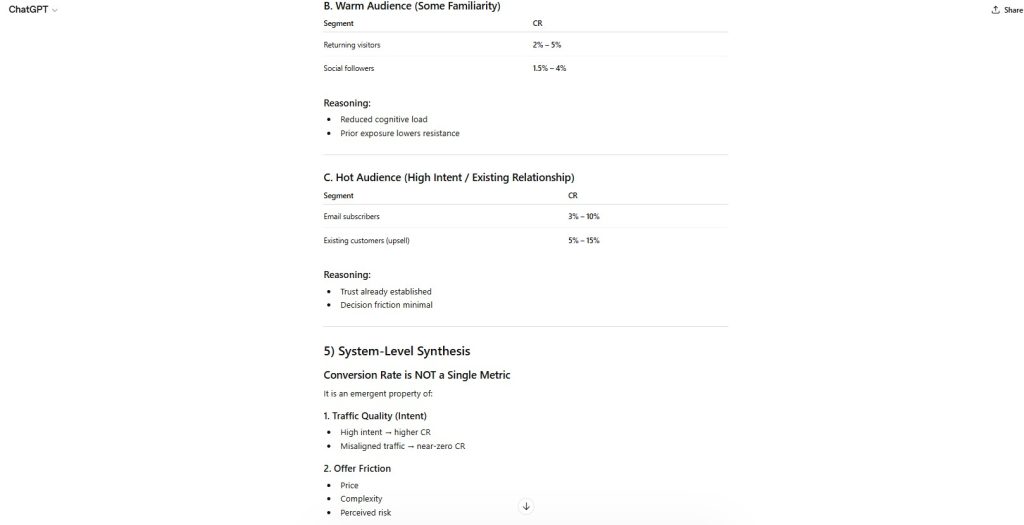
Figure 6 — Hidden Assumption Layering
The estimates assume a standard business model, traffic quality, and funnel structure without explicitly stating those assumptions.
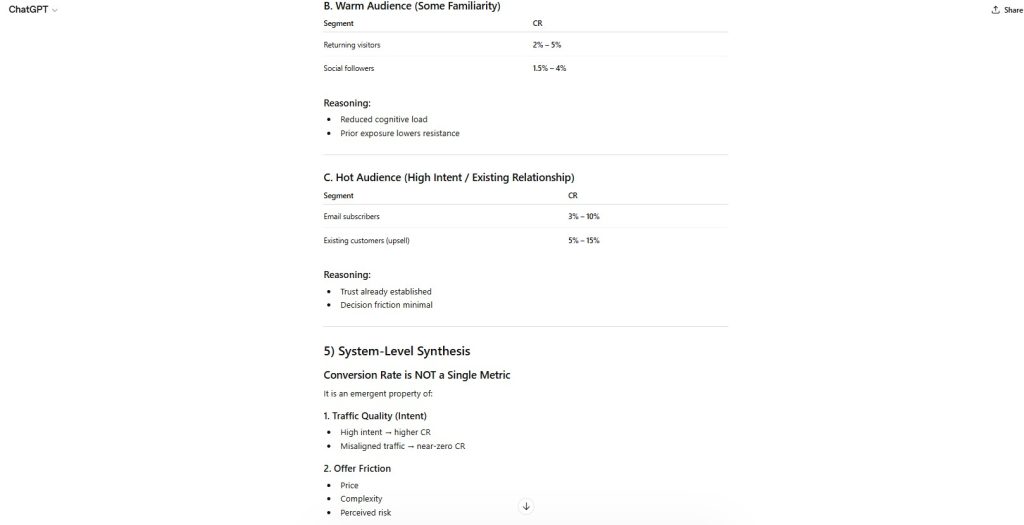
Figure 7 — Plausibility Framing Through Reasoning
The model uses trust, intent, and funnel logic to reinforce the credibility of the numerical ranges.

Figure 8 — Final Logical Assessment
The model produced plausible but unverified numerical specificity under undefined conditions.
Capability Domain Evaluated
Quantitative Reasoning / Estimation Integrity
This domain tests the model’s ability to:
- produce estimates with appropriate uncertainty
- distinguish plausible ranges from validated benchmarks
- avoid fabricated precision under underspecified conditions
- state assumptions explicitly when context is incomplete
- maintain numerical discipline when evidence is unavailable
Observed Strengths
- Strong structural organization
- Clear segmentation across multiple dimensions
- Internally consistent numerical presentation
- Reasoning that is coherent and easy to follow
- Stable formatting and analytical tone
The output demonstrates strong capability in constructing plausible quantitative responses.
Observed Constraints
- No source attribution for numerical ranges
- No dataset or benchmark grounding
- No industry or business-model constraints
- No quantified uncertainty beyond narrow ranges
- Embedded assumptions are not declared
The model produces decision-like numbers without establishing evidentiary support.
Failure Mode Classification
False Specificity / Fabricated Precision
The model generates precise-looking numerical estimates without sufficient empirical grounding.
Institutional Assessment
The model demonstrates strong capability in producing structured and plausible quantitative outputs under ambiguous conditions.
It successfully:
- organizes estimates across multiple business dimensions
- presents values in a professional, decision-oriented format
- supports those values with internally coherent reasoning
However:
- it does not distinguish between plausible estimation and validated benchmark data
- it does not constrain outputs to a defined business context
- it does not sufficiently signal the absence of empirical grounding
This results in apparent quantitative authority without traceable evidence.
Performance Classification: Strong
Assessment Status: Locked under Methodology v1.0
Structural revisions require formal version update
— First Tier Review
Leave a Reply